小编的话:本文译自https://flyyufelix.github.io/2018/09/11/donkey-rl-simulation.html
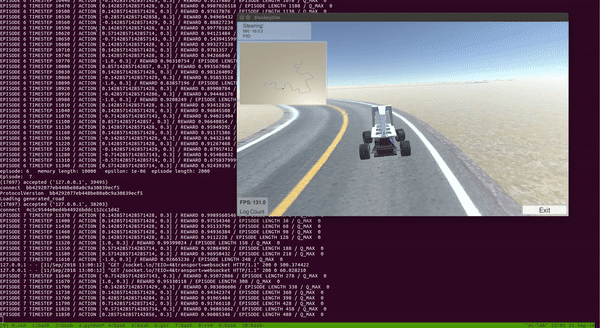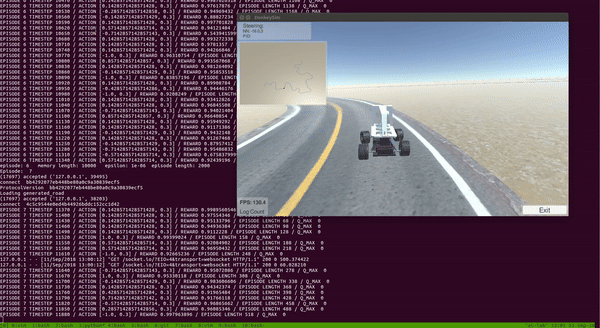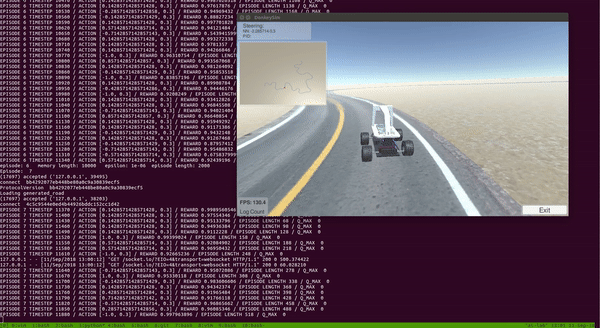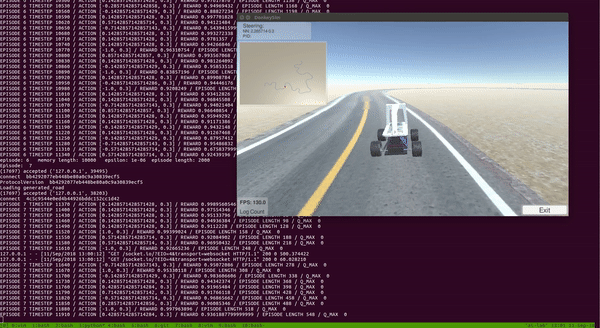
Donkey Car在Unity Simulator中使用Double Deep Q Learning(DDQN)进行训练。
1.简介
Donkey Car是一款适用于小型RC车的开源DIY自动驾驶平台。对于那些想要了解更多关于自动驾驶但却没有知识或背景来构建无人车的人,该平台提供了自己构建一台所需的所有细节。它涵盖了硬件和软件堆栈。按照指南,任何人都能够在没有任何硬件背景的情况下组装汽车。
现在,训练汽车进行自动驾驶的最常用方法是行为克隆(behavioral cloning)和线路跟踪(line following)。在高层次上,行为克隆通过使用卷积神经网络通过监督学习来学习汽车图像(由前置摄像头拍摄)与转向角度和油门值之间的映射。另一种方法,即线路跟踪,通过使用计算机视觉技术来跟踪中线并利用PID控制器使汽车跟随线路。我尝试了两种方法,他们都工作!

Donkey Cars通过行为克隆训练以避开障碍
(视频于2018年5月12日在香港举行的当地Donkey Car Meetup上拍摄)
2.用强化学习训练Donkey Car
从本质上讲,Donkey Car的目标是制造最快的自动驾驶汽车以参加比赛(在赛道上完成单圈的最快时间)。我认为强化学习是训练赛车的好方法。我们只需要设计一个奖励,使汽车的速度最大化、同时让它保持在赛道区域内,并让算法弄清楚其余部分。听起来很容易吗?然而,实际上,在物理环境中训练强化学习被证明是非常具有挑战性的。强化学习基本上是通过反复试验来学习的,如果不是不可能的话,让汽车在现实世界中随机驱动几个小时并等待(或祈祷)它在撞成碎片前开始学习是非常困难的。训练持续时间也是一个问题,因为RL代理往往要经过数百个迭代才能学习到需要的参数。因此,强化学习很少在物理环境中进行。
3.从模拟到现实
最近,有一些关于模拟到现实的研究,即首先使用强化学习在虚拟模拟器中训练汽车,然后将训练有素的代理转移到现实世界。例如,OpenAI最近训练了一个类似人类的灵巧机器人手来操纵物体,整个训练是在模拟器中进行的; 在另一项实验中,Google Brain训练了一个四足机器人(Ghost Robotics Minitaur)来学习使用模拟到现实技术的敏捷运动。控制策略在模拟器中学习,然后成功部署在真实机器人上。因此,看起来为了训练Donkey Car进行强化学习,一种可行的方法是让它先接受模拟训练,然后将学到的策略移植到真车上。

OpenAI在模拟中训练了具有RL的灵巧机器人手,并将策略转移到现实世界来操纵物理立方体
4.Donkey Car模拟器
第一步是为Donkey Car 创建一个高保真模拟器。幸运的是,Donkey Car社区的某个人在Unity中慷慨地创建了一个Donkey Car模拟器。但是,它专门用于执行行为学习(即将相应的转向角保存相机图像并在文件中调节值以进行监督学习),但根本不能满足强化学习的需要。我期待的是OpenAI体育馆之类的界面,我可以通过调用reset()重置环境和step(action)逐步环境来操纵模拟环境。好吧,我决定从现有的Unity模拟器开始,并进行一些修改,使其与强化学习兼容。
4.1 建立一种让Python与Unity通信的方法
由于我们将在python中编写强化学习代码,因此我们必须首先找到一种方法来使python与Unity环境进行通信。事实证明,由Tawn Kramer创建的Unity模拟器还带有用于与Unity通信的python代码。通信是通过Websocket协议完成的。与HTTP不同,Websocket协议允许服务器和客户端之间的双向通信。在我们的例子中,我们的python“服务器”可以直接将消息推送到Unity(例如转向和节流动作),我们的Unity“客户端”也可以将信息(例如状态和奖励)推送回python服务器。
除了Websocket之外,我还简要地考虑过使用gRPC。gRPC是一个高性能的服务器 – 客户端通信框架,由Google于2016年8月底开源。它被Unity采用作为其ml-agents插件的通信协议。但是,它的设置有点麻烦(即需要以protobuf格式定义RPC数据结构和方法)并且性能增益不值得。所以我决定坚持使用Websocket。
4.2 为Donkey Car创建一个定制的OpenAI Gym环境
下一步是创建一个类似于OpenAI Gym的界面,用于训练强化学习算法。对于那些之前接受过强化学习算法训练的人来说,您应该习惯使用一组API来使RL代理与环境进行交互。常见的有reset(),step(),is_game_over(),等,我们可以通过自定义我们自己的Gym环境扩展OpenAI Gym类和实施上述方法。
由此产生的环境与OpenAI Gym兼容。我们可以使用熟悉的Gym界面与Donkey环境进行交互:
env = gym.make(“donkey-v0”)
state = env.reset()
action = get_action()
state, reward, done, info = env.step(action)
环境还允许我们设置frame_skipping并在无头模式下训练RL代理(即没有Unity GUI)。
与此同时,有3个Unity场景可供使用(由Tawn Kramer创建):生成的道路,仓库和用于训练的Sparkfun AVC。在我们开始运行自己的RL训练算法之前,我们必须自己构建Donkey Car Unity环境(需要安装Unity)或下载预构建的环境可执行文件。如何设置环境的训练RL详细说明可在我的GitHub页面找到。
